Server-Side Proving vs Client-Side Proving

TL;DR
The location of proof generation is a core architectural decision that directly affects performance, privacy, trust assumptions, and user experience.
Server-side proving excels at scale and speed through batching and powerful infrastructure, but increases centralization and exposes sensitive inputs to trusted servers.
Client-side proving keeps data under user control and aligns with self-sovereign systems though could be prone to constraints.
Introduction
Zero-knowledge proofs and verifiable computation have moved from academic theory into production systems. They now secure rollups, power privacy-preserving identity systems, enforce compliance rules, and verify off-chain computation across blockchains and enterprises.
As these systems mature, architectural decisions that once seemed secondary now shape performance, privacy, trust, and long-term scalability. One of the most significant consequences of these decisions is simple:
Where should proof generation happen: on the server or on the client?
At first glance, this may look like a deployment detail. In practice, it defines who controls computation, who sees sensitive data, how fast proofs can be produced, and how much trust users must place in infrastructure they do not own.
This article explores server-side and client-side proving in depth. You will learn how each model works, what trade-offs it introduces, and how modern systems increasingly combine both approaches. By the end, you should have a clear framework for choosing the right proving architecture for your application.
Background: Understanding Proving in Verifiable Systems
Before comparing architectures, it helps to ground the discussion in first principles. In zero-knowledge and verifiable computation systems, proving refers to the process of generating a cryptographic proof that a computation was executed correctly. The proof convinces a verifier that a statement is true without requiring the verifier to rerun the computation or, in zero-knowledge systems, without revealing private inputs.
Every such system has three core components:
- The prover, which performs the computation and generates the proof.
- The verifier, which efficiently checks the proof.
- The circuit or program that defines the computation being proven.
The location of the prover matters because proof generation is computationally expensive. Generating a proof can require orders of magnitude more resources than verifying one. As a result, deciding where the prover runs is not just an optimisation choice. It is a foundational architectural decision.
Today, proving is used across a wide range of environments, including blockchain rollups, decentralized identity systems, compliance and audit tooling, oracle networks, and off-chain computation frameworks. Each of these contexts places different demands on privacy, throughput, cost, and user experience.
What Is Server-Side Proving?
Server-side proving means that proofs are generated on a centralized or semi-centralized infrastructure controlled by an operator. Users or applications send inputs to a server, which executes the computation, generates the proof, and returns the result.
In a typical workflow, a client submits data to an API. The server then runs the proving system, often on specialized hardware, and publishes or returns the resulting proof to be verified elsewhere, such as on-chain or by another service.
The server then runs the proving system, often on specialized hardware, and publishes or returns the resulting proof to be verified elsewhere, such as on-chain or by another service. This is where Bonsol foundational network operates today, providing dedicated, high-performance infrastructure that handles proof generation reliably at scale.
Most server-side proving systems run on cloud infrastructure. This may include CPU clusters, GPUs, or purpose-built proving farms optimized for parallel workloads.
Advantages of Server-Side Proving
The primary advantage of server-side proving is performance. Servers can be provisioned with high-end hardware that far exceeds what most users carry in their pockets. This enables faster proving times, higher throughput, and support for more complex circuits.
Server-side proving also allows batching and parallelization. Multiple proofs can be generated simultaneously, reducing costs across users and improving overall efficiency. This is particularly important for rollups, bridges, and high-frequency DeFi systems where latency and throughput directly affect usability.
Operationally, server-side systems are easier to maintain. Upgrades to circuits, proving keys, or hardware can be rolled out centrally without requiring user intervention. For fast-moving systems, this flexibility is often essential.
Limitations and Risks of Server-Side Proving
The performance benefits of server-side proving come with trade-offs.
Most importantly, server-side proving increases trust assumptions. Users must trust that the server executes the computation correctly and does not misuse or leak sensitive inputs. While the proof guarantees the correctness of the computation, it does not guarantee the correct handling of private data before proving.
Privacy in proving is not a binary choice; it is a spectrum. At one end, fully client-side proving keeps inputs entirely on the user’s device, maximizing privacy but often at the cost of performance, latency, and user experience. At the other end, fully server-side proving delivers speed and scale, but introduces trust assumptions around who operates the infrastructure and how sensitive data is handled. Most production systems live between these extremes.
Bonsol operates deliberately in this middle ground. Built on RISC Zero’s prover network, Bonsol leverages zero-knowledge proofs alongside segmented proving and recursive aggregation, where complex computations are split into smaller shards, proven independently, and combined into a single final proof. This design ensures correctness without revealing private inputs, while also limiting how much information any single prover node ever sees. Combined with diligent management of vetted and trusted prover node operators, Bonsol reduces the trust surface area and data exposure inherent in server-side proving. The result is a pragmatic model of semi-privacy: strong enough for real-world verifiable finance applications, yet performant and scalable enough to run in production today.
What Is Client-Side Proving?
Client-side proving shifts proof generation to the end user’s environment. The prover runs locally, on a browser, mobile device, wallet, or desktop application. Inputs never leave the user’s device, and only the proof is shared.
In this model, the user controls both the data and the proving process. The server, if one exists at all, acts only as a verifier or relay.
Client-side proving workflows typically involve downloading proving keys and circuits ahead of time, executing the computation locally, and submitting the resulting proof for verification.
Advantages of Client-Side Proving
The defining strength of client-side proving is privacy. Because sensitive inputs never leave the user’s device, there is no need to trust external infrastructure with private data. This aligns naturally with self-custody models, decentralized identity systems, and user-sovereign applications.
Client-side proving also reduces reliance on centralized operators. The system becomes more resilient to censorship and infrastructure failures, since each user can generate proofs independently.
From a philosophical standpoint, client-side proving embodies the original promise of zero-knowledge systems: verifiability without trust.
Limitations and Challenges of Client-Side Proving
The challenges of client-side proving are practical rather than conceptual.
Proof generation is expensive. On consumer hardware, especially mobile devices, proving can be slow and resource-intensive. Long-proving times degrade user experience and can drain batteries or overheat devices.
Hardware diversity adds another layer of complexity. A circuit that runs comfortably on a high-end laptop may be unusable on a low-end phone. This limits the size and complexity of computations that can realistically be proven client-side.
As a result, client-side proving is often constrained to simpler circuits or infrequent operations.
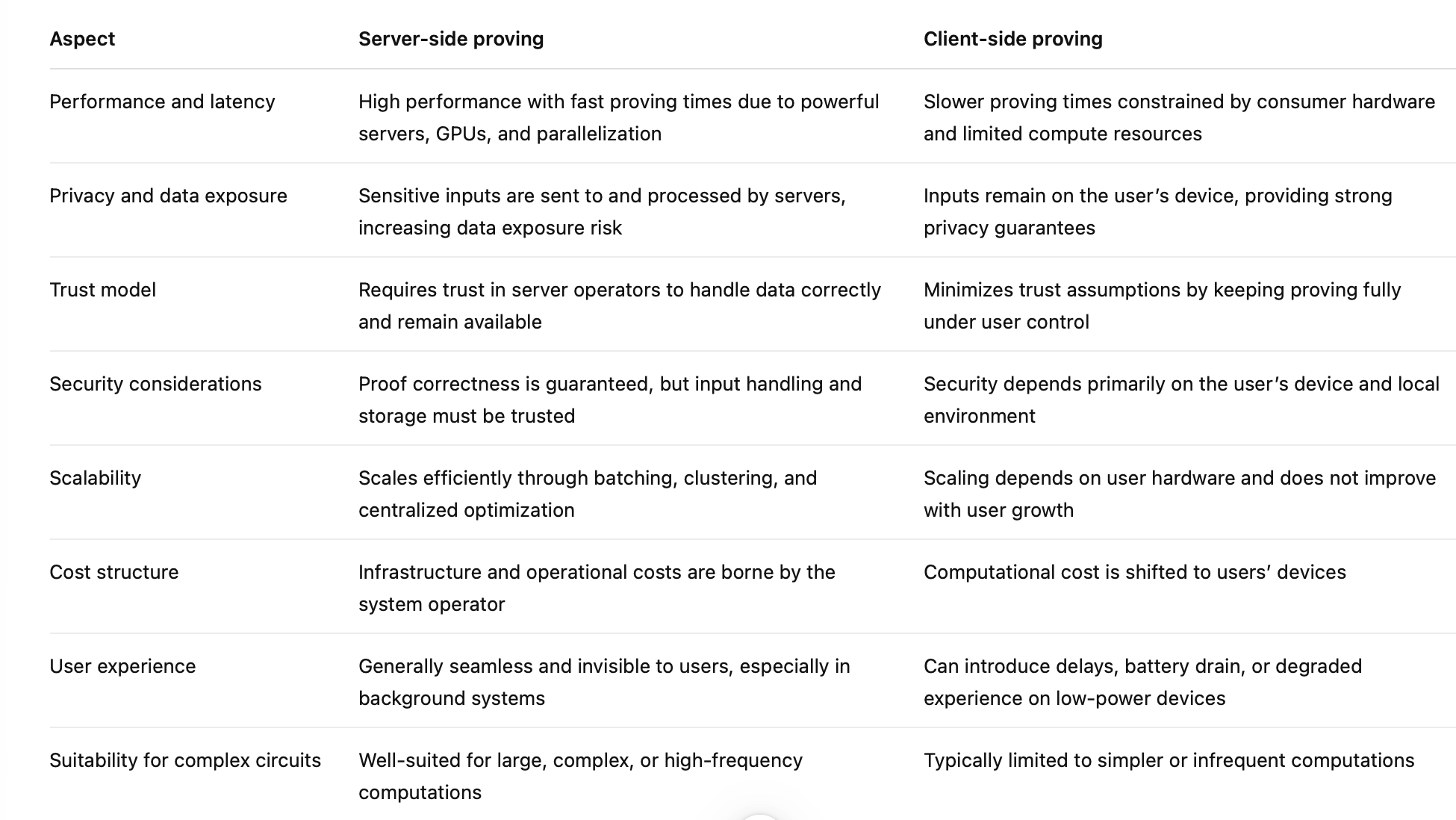
Key Differences Between Server-Side and Client-Side Proving
Hybrid and Delegated Proving Models
In practice, many modern systems reject a strict binary choice and adopt hybrid proving architectures.
Hybrid models split responsibilities between client and server. For example, a client may preprocess or encrypt inputs, while a server performs heavy computation without learning sensitive data. Other systems use delegated proving, where a client authorizes a third party to generate a proof under strict constraints.
Techniques such as secure enclaves, multi-party computation, and encrypted inputs allow servers to assist with proving while reducing trust requirements. These approaches aim to combine the performance of server-side proving with the privacy guarantees of client-side execution.
Use Cases and When to Choose Each Model
Different applications naturally align with different proving architectures.
High-throughput systems such as rollups, DeFi protocols, and bridges typically rely on server-side proving. The performance requirements are too demanding for widespread client-side execution.
Privacy-sensitive applications, including identity, credentials, and selective disclosure compliance systems, benefit from client-side proving. Here, minimizing data exposure outweighs raw speed.
Mobile and wallet-based applications often require careful trade-offs. Lightweight client-side proving may work for simple checks, while heavier proofs are delegated.
Enterprise and regulated environments frequently prefer controlled server-side proving combined with strong auditability and compliance guarantees.
For architects and protocol designers, the key decision criteria include performance needs, privacy requirements, trust assumptions, regulatory constraints, and expected user hardware.
Conclusion
At Bonsol, we focus on building infrastructure that makes verifiable computation usable in real systems. That means confronting trade-offs directly rather than pretending they disappear with the right abstraction. Privacy, trust, and scalability are shaped less by ideology and more by where and how proofs are generated.
Client-side and server-side proving are not opposing philosophies. They are tools. Each performs well under different constraints, and strong systems are explicit about why they choose one, the other, or a combination of both. Where proofs are generated determines who must be trusted, how data is exposed, and how far a system can scale.
Today, Bonsol’s prover network provides a production-grade foundation for server-side proving, with safeguards such as vetted prover operators, careful operational oversight, and proof segmentation to limit data exposure. In parallel, QCash represents our exploration of client-side proving, pushing toward maximum privacy by keeping sensitive inputs on the user’s device.
Together, these efforts reflect where we are building toward: a hybrid model that supports both server-side and client-side proving, allowing the Bonsol platform to offer a spectrum of privacy and trust guarantees based on application needs.
The key takeaway is simple. Proving location is not an implementation detail. It is a core system design choice, and Bonsol is being built to give teams the flexibility to make that choice deliberately, without sacrificing practicality or scale.